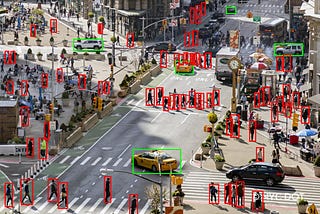
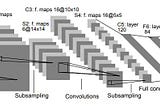
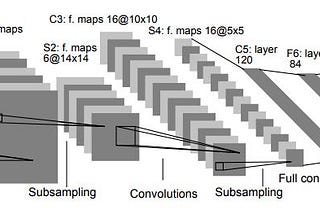
PinnedAlexey ZinovievLeNet-5 in Kotlin with TensorFlowIn my previous article, I showed how you can train a linear regression model in Kotlin using Tensorflow API. Let’s implement LeNet-5 CNN.10 min read·Apr 30, 2020----
PinnedAlexey ZinovievKotlinDL 0.3Introducing version 0.3 of our deep learning library, KotlinDL.10 min read·Sep 27, 2021----
PinnedAlexey ZinovievKotlin DL Version 0.2:Introducing version 0.2 of our deep learning library, KotlinDL.7 min read·May 17, 2021----
PinnedAlexey ZinovievTheory and practice of hyperparameter tuning with Apache Ignite MLHow to build the best model18 min read·Dec 9, 2020----
Alexey ZinovievKotlinDL 0.4Version 0.4 of our deep learning library, KotlinDL, is out!7 min read·Jun 9, 2022----
Alexey ZinovievSure, I've experimented with a few PyTorch models, loading them via ONNX.1 min read·Jan 27, 2022----
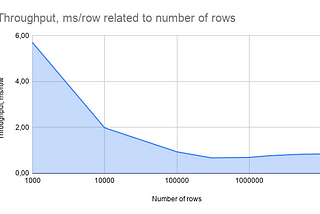
Alexey ZinovievApache Ignite ML Performance ExperimentSpoiler: The reported data is not an official benchmark with reproducible results and shared code, but the numbers can help with…9 min read·Nov 27, 2020----
Alexey ZinovievApache Ignite ML: possible use cases, racing with Spark ML, plans for the futureHi, distributed programmers! This is the second post in a series of posts about Ignite ML library.4 min read·Nov 12, 2020----
Alexey ZinovievApache Ignite ML: origins and developmentHi, distributed programmers! Nice to see you here, in my technical blog. Gird your loins and read this long, long article about Apache®…6 min read·Nov 4, 2020----